CARTE BLANCHE AUX JEUNES CHERCHEURS
Communication de crise via les médias sociaux : collecte, stockage et analyse des données
Table des matières
Texte intégral
1Depuis le début du siècle, les services de communication via Internet ont augmenté leur présence dans toute la sphère des activités humaines, qu’elles soient de type professionnelle et privée. Ces services ont également modifié la communication en situation de crise, quelle que soit la nature de la crise, par exemple politique, industrielle ou de l’ordre d’une catastrophe naturelle. En fait, traditionnellement, les sources institutionnelles ont créé et géré un flux d’information unidirectionnel, partant des autorités vers les victimes et cristallisant ainsi les responsabilités de chaque acteur pendant la crise. Depuis une dizaine d’années, cette conception se révèle peu adéquate en raison des possibilités de communication offertes par des services numériques, appelés « médias sociaux ». Plus précisément, grâce aux informations transmises et partagées en temps réel via les médias sociaux, comme Twitter et Facebook, des victimes peuvent alerter les autorités pour permettre le sauvetage d’autres victimes, elles peuvent communiquer directement entre elles et développer leurs propres connaissances et points de repère pour agir afin de faire face à la situation. Les informations transmises par les victimes via les médias sociaux rendent la communication de crise persistante, facilitant ainsi son étude grâce à la constitution de corpus représentatifs dont la constitution ouvre des problèmes méthodologiques importants, concernant toute la chaîne de production de corpora.
2L’objectif de notre contribution est de souligner ces problèmes et indiquer des solutions à adopter. Après avoir synthétisé les usages des médias sociaux en situation de crise (section 1), nous aborderons des problèmes spécifiques concernant : 2) la sélection et la collecte des contenus créés par les utilisateurs via les MS, 3) les technologies pour assurer le stockage des échanges via les médias sociaux, et 4) les méthodes à envisager pour en permettre l’analyse.
Usages des médias sociaux en situation de crise
3Les médias sociaux permettent aux internautes de créer des profils publics ou semi-publics, de maintenir une liste d’utilisateurs avec lesquels ils partagent une connexion, et de naviguer à travers cette liste et celles maintenues par d’autres utilisateurs (Boyd & Ellison, 2008). Ils comprennent notamment les plateformes de microblog telles que Twitter, les sites de partage de contenus comme Youtube ou Flickr, et les réseaux socio-numériques tels que Facebook.
4Au cours de dernières années, les analystes de la communication se sont appropriés de ces médias sociaux pour étudier les contenus et les processus communicationnels avant, pendant et après une situation de crise (Palen, Vieweg, Liu, & Hughes, 2009). En janvier 2009, pour la première fois, Twitter devance les journalistes pour la couverture d’un événement de grande ampleur : l’amerrissage d’urgence d’un avion sur l’Hudson River (Fig. 1). Les institutions ont ensuite, à leur tour, utilisé cette plateforme de microblogging pour la diffusion d’informations en temps réel, comme durant l’accident nucléaire de Fukushima Daiichi (2011) (Fig. 2) et même, plus récemment, pour mobiliser le crowdsourcing lors des attentats de Boston en 2013 (Fig. 3).
Fig. 1 – https://twitter.com/jkrums/status/1121915133

Fig. 2 – https://twitter.com/iaeaorg/status/47131927093846016

Fig. 3 – https://twitter.com/bostonpolice/status/323895934402580480

5Cette appropriation s’est accompagnée de l’émergence de nouveaux usages, pour favoriser la diffusion de l’information. En effet, en situation de crise, les utilisateurs de Twitter privilégient la rediffusion de messages existants et le partage de liens, plutôt que l’envoi de messages personnels (Hughes & Palen, 2009). Sur le service de partage d’images Flickr, les mots clefs (hashtags) utilisés pour indexer les contenus liés à une crise font l’objet de recommandations définies par les utilisateurs eux même (Liu, Palen, Sutton, Hughes, & Vieweg, 2008). Enfin, lors de la fusillade de Virginia Tech en 2007, les étudiants et leurs proches ont mené un travail collaboratif de collecte d’informations et de vérification des sources afin d’établir, avant les annonces officielles, la liste des victimes (Palen et al., 2009). Ces outils favorisent ainsi une gestion hautement parallèle et distribuée de la situation de crise (Palen et al., 2010).
6En outre, les médias sociaux facilitent l’étude de la communication de crise. En rendant persistants des échanges autrefois éphémères, ils offrent aux chercheurs de nombreuses opportunités pour la collecte et l’analyse de cette communication (Palen et al., 2009). Internet peut ainsi être utilisé comme un outil pour étudier non seulement ses utilisateurs mais, plus largement, la société dans laquelle ils s’inscrivent (Rogers, 2009).
Collecte des contenus générés par les utilisateurs
7La majorité des plateformes de médias sociaux comportent des interfaces de programmation (ou API – Application Programming Interface), permettant aux développeurs, sous certaines conditions, d’accéder aux profils des utilisateurs, à leurs relations et aux contenus qu’ils publient. Après s’être authentifié, le développeur (client) peut envoyer des requêtes à la plateforme (serveur) qui répond par les données correspondantes. Cependant, la majorité de ces fonctionnalités sont soumises à des quotas, principalement pour limiter les ressources (temps de calcul, bande passante) requises par l’infrastructure supportant l’API. Les plateformes proposent des offres commerciales pour lever certaines de ces contraintes, générant ainsi des inégalités pour l’accès aux données (Borra & Rieder, 2014)
8Une des limitations les plus contraignantes pour les chercheurs est celle portant sur l’ancienneté des contenus. Ainsi, sur Twitter, il n’est pas possible, via l’API standard, d’accéder, par exemple lors d’une requête portant sur un mot clef, à des messages antérieurs à une semaine. Un corpus portant sur un événement donné ne peut donc être constitué a posteriori.
9La constitution de corpus en temps réel via les APIs standards nécessite l’envoi régulier de requêtes portant sur les derniers contenus publiés. Pour garantir l’exhaustivité de cette collecte, les requêtes doivent être effectuées à une fréquence très élevée, nécessitant une infrastructure performante. Afin de répondre à ce type de besoins, et d’épargner à leurs serveurs un tel bombardement de requêtes, plusieurs plateformes de médias sociaux ont mis en place des APIs spécialement conçues pour la collecte en temps réel. Après avoir reçu une seule requête, l’API renvoie, à mesure qu’ils sont publiés, les contenus correspondant, via une connexion persistante (dans le cas de Twitter) ou des notifications de type push (Flickr, Instagram).
10Les APIs « en temps réel » offrent différents critères de collecte, permettant notamment de recevoir les derniers contenus publiés par un utilisateur donné, associés à certains mots clefs, ou encore provenant d’une zone géographique spécifique. Les critères utilisés pour la création d’un corpus sont capitaux, puisqu’ils constitueront la principale limite à l’interprétation des résultats. Le choix d’un mot clefs, d’un groupe d’utilisateur ou d’une zone géographique traduit une hypothèse préalable du chercheur quant au périmètre du phénomène qu’il étudie (Gerlitz & Rieder, 2013). Ici, nous nous intéresserons tout particulièrement aux APIs temps réel de Twitter, Flickr et Instagram, car elles permettent la collecte basée sur un mot clef pour l’ensemble des utilisateurs (tandis que d’autre, comme Youtube, n’offrent cette fonctionnalité que pour un utilisateur ou un groupe d’utilisateurs donné).
11Plusieurs outils ont été conçus pour faciliter l’usage de ces APIs, intégrant des interfaces graphiques, voir même le stockage et l’analyse des données. YourTwapperKeeper (Bruns & Liang, 2012) permet la collecte de tweets par mot clef et leur stockage dans une base de données. Également dédié à Twitter, DMI-TCAT (Borra & Rieder, 2014) offre de nombreux critères de collecte, un système de stockage, mais aussi de nombreux outils d’analyse des tweets. En l’absence de besoins spécifiques nécessitant le développement de nouveaux outils, l’utilisation d’outils existants, si possible open-sources, facilite la reproductibilité des résultats (Borra & Rieder, 2014).
Technologies du Web Sémantique pour le stockage des données
12Les APIs des différentes plateformes de médias sociaux fournissent leurs données dans des formats variés : types de fichier, structures, champs présents, formats de dates … L’analyse conjointe de données provenant de plusieurs plateformes nécessite donc la création d’une représentation unifiée de ces contenus, ce que permettent les technologies du Web Sémantique (Breslin, Passant, & Decker, 2009).
13Le Web Sémantique peut être défini comme une extension du Web actuel, liant des connaissances, définies de manière formelles, plutôt que de simples documents, favorisant ainsi les traitements automatisés (Berners-Lee, Hendler, & Lassila, 2001). C’est le modèle RDF (Resource Description Framework – Cadre de description de ressource) qui est utilisé pour décrire les connaissances atomiques sous forme de triplets {sujet, prédicat, objet}. La structuration de ces connaissances est, elle, assurée par la définition d’ontologies, décrivant les concepts, leurs relations et les contraintes les régissant (Breslin et al., 2009).
14Il existe d’or et déjà plusieurs ontologies permettant la représentation des plateformes des médias sociaux, de leurs utilisateurs et de leurs interactions (Breslin et al., 2009). SIOC (Semantically Interlinked Online Communities) est dédiée à la description des communautés en lignes et de leurs échanges. FOAF (Friend Of A Friend) permet la représentation des individus, de leurs relations, de leurs identités en ligne. DC (Dublin Core) fournit un large vocabulaire pour les métadonnées des documents, pouvant également être utilisé pour les contenus générés sur les médias sociaux.
Fig. 4 – https://twitter.com/Laurent90100/statuses/446626233213026304

Fig. 5 – Représentation du tweet de la Fig. 4 sous forme de triplets RDF
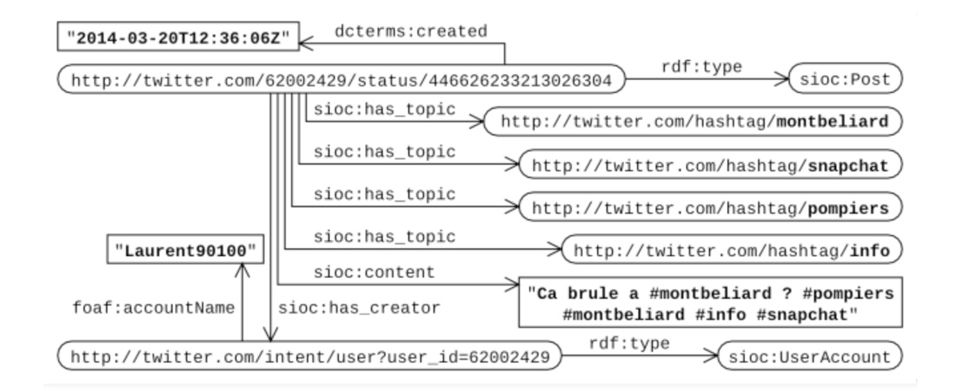
15La représentation unifiée des données issues de plusieurs plateformes doit permettre de créer des liens entre les objets de ces différentes plateformes, afin de faciliter leur analyse conjointe. Des liens de similarité (tels que owl :sameAs) pourront être utilisés afin d’associer les hashtags semblables sur les différentes plateformes. Ainsi, une simple requête pourra filtrer les contenus associés à un hashtag quelle que soit leur plateforme d’origine. Le même système pourrait être appliqué aux utilisateurs, via la détection automatique des comptes tenus par une même personne.
Analyse des échanges sur les médias sociaux
16Les métadonnées (date, auteur, mots clefs) stockées sous forme de triplets RDF (Fig 5) peuvent être analysées à l’aide de SPARQL, le langage de requête dédié aux données RDF. Cette analyse peut exploiter différents types de métriques, portant sur les publications (les plus partagées, les plus commentées), les utilisateurs (les plus actifs, les plus mentionnés), les mots clefs (les plus utilisés, les co-occurences les plus fréquentes). L’ensemble de ces métriques peut également être calculé sur des intervalles temporels réguliers, pour en analyser l’évolution (Bruns & Liang, 2012).
17L’analyse structurale des réseaux peut être exploitée pour étudier des graphes homogènes d’utilisateurs (abonnement, mention, rediffusion, réponse) (Hui, Tyshchuk, Wallace, Magdon-Ismail, & Goldberg, 2012) ou de mots clefs (co-occurence) mais aussi des réseaux hétérogènes tels que les mots clefs associés aux URLs partagées (Bruns & Liang, 2012). Cette méthode d’analyse offre de nombreuses métriques permettant d’étudier le graphe dans son ensemble, ou la position d’un nœud spécifique.
18L’analyse peut également porter sur le contenu textuel des publications, grâce aux techniques de traitement du langage naturel (NLP – Natural Language Processing). Celles-ci permettent notamment l’analyse des sentiments (positif ou négatif) et des émotions (peur, colère, tristesse), ainsi que l’extraction de thèmes, et d’expressions fréquemment utilisées (bi- ou tri-grammes) (Yang & Kavanaugh, 2011). Elles peuvent également être utilisées pour la reconnaissance d’entités nommées et leur annotation sémantique.1
19Afin d’éviter toute généralisation invalide, l’interprétation des résultats ne doit se faire que dans les limites issues des choix méthodologiques lors de la collecte (plage temporelle, capture en temps réel ou non, requête par mots clefs, utilisateurs, ou zone géographique) et de l’analyse (métriques calculées, éventuels traitements effectués). En outre, les résultats obtenus doivent être considérés en relations avec les outils utilisés (pour la collecte comme pour l’analyse), en raison des potentiels artefacts liés à leur fonctionnement (Bruns & Liang, 2012). Enfin, lors d’études portant sur plusieurs plateformes différentes, les spécificités de chacune doivent être prises en compte, leurs affordances respectives (Rogers, 2009) pouvant générer d’importantes différences d’usages, limitant la portée des résultats.
Conclusion
20Au cours des dernières années, les médias sociaux sont devenus un terrain d’étude privilégié pour étudier la communication en situation de crise. Ces mêmes services web sont également de précieux outils pour étudier la société qui les utilise. Les interfaces de programmation fournies par les plateformes socio-numériques permettent la constitution de corpus exhaustifs des échanges entre les utilisateurs, ainsi que l’accès à de nombreuses données relatives à ces utilisateurs. Nous avons présenté une méthode exploitant les technologies du Web Sémantique pour construire une représentation unifiée des contenus échangés sur les médias sociaux, permettant l’étude conjointe de plusieurs plateformes. Un grand nombre d’outils et de méthodes existants peuvent enfin être exploités pour analyser le contenu et les métadonnées de ces messages.
21Néanmoins, à chaque étape de collecte, de traitement et d’analyse, les outils et les méthodes employés altèrent les données, impactant les résultats. Comme aucun outil n’est neutre, la démarche scientifique exige que tout chercheur ne doive pas considérer ces services informatiques comme autant de boîtes noires, mais tenter d’en comprendre le fonctionnement, afin de déterminer et de limiter leur influence. Le succès de cette opération réside dans l’association des méthodes issues des disciplines des sciences de l’information, de l’informatique et des sciences humaines et sociales.
Bibliographie
BERNERS-LEE T., HENDLER J. & LASSILA O. (2001). The semantic web. Scientific American, 284(5), pp. 28-37.
BORRA E. & RIEDER B. (2014). Programmed Method : Developing a Toolset for Capturing and Analyzing Tweets. Aslib Journal of Information Management, 66(3), p. 3-3.
BOYD Danah M. & ELLISON N. B. (2008). Social Network Sites : Definition, History, and Scholarship. Journal of Computer-Mediated Communication, 13(1), pp. 210-230.
BRESLIN J. G., PASSANT A. & DECKER S. (2009). The Social Semantic Web. Springer.
BRUNS A. & LIANG Y. E. (2012). Tools and methods for capturing Twitter data during natural disasters. First Monday, 17(4).
GERLITZ C. & RIEDER B. (2013). Mining One Percent of Twitter : Collections, Baselines, Sampling. M/C Journal, 16(2).
HUGHES A. L. & PALEN L. (2009). Twitter adoption and use in mass convergence and emergency events. International Journal of Emergency Management, 6(3), 248–260.
HUI C., TYSHCHUK Y., WALLACE W. A., MAGDON-ISMAIL M. & Goldberg M. (2012). Information cascades in social media in response to a crisis: a preliminary model and a case study (pp. 653–656).
LIU S. B., PALEN L., SUTTON J., HUGHES A. L. & VIEWEG S. (2008). In search of the bigger picture: The emergent role of on-line photo sharing in times of disaster.
PALEN L., ANDERSON K. M., MARK G., MARTIN J., SICKER D., PALMER M. & GRUNWALD D. (2010). A vision for technology-mediated support for public participation & assistance in mass emergencies & disasters (p. 8).
PALEN L., VIEWEG S., LIU S. B. & HUGHES A. L. (2009). Crisis in a networked world features of computer-mediated communication in the April 16, 2007, Virginia Tech Event. Social Science Computer Review, 27(4), pp. 467-480.
ROGERS R. (2009). The End of the Virtual : Digital Methods. Amsterdam: Amsterdam University Press.
YANG S. & KAVANAUGH A. L. (2011). Half-Day Tutorial: Collecting, Analyzing and Visualizing Tweets using Open Source Tools.
Notes
Pour citer ce document
Quelques mots à propos de : Antonin Segault
Équipe Objets et Usages Numériques. Laboratoire ELLIADD. Université de Franche-Comté
Quelques mots à propos de : Federico Tajariol
Équipe Objets et Usages Numériques. Laboratoire ELLIADD. Université de Franche-Comté
Quelques mots à propos de : Ioan Roxin
Équipe Objets et Usages Numériques. Laboratoire ELLIADD. Université de Franche-Comté