Questions de recherche
Le « Grand Oral » : une épreuve pédagogique de mise en situation au service des étudiants de Master
Table des matières
Texte intégral
01 janvier 2023
41-55
Introduction
1Le « Grand Oral » est une épreuve commune aux étudiants de master 21 de l’UFR Ingémédia (Université de Toulon). Cet exercice individuel consiste à donner plusieurs consignes à un étudiant qui présente oralement, 48 h plus tard, son travail devant un jury constitué de deux enseignants. Dans le cadre de l’ancienne offre de formation, cette épreuve était étalée sur une semaine pour les étudiants du master 2 « Intelligence Economique et Territoriale » (IET)2 car les propositions devaient être ambitieuses et répondre à une problématique précise. Cet article propose de revenir sur une étude présentée en 2018 afin d’illustrer les différentes possibilités offertes aux étudiants pour répondre aux exigences à la fois techniques et méthodologiques, tout en construisant une démarche scientifique ancrée en Sciences de l’Information et de la Communication (SIC). La promotion 2017/2018 avait ainsi travaillé sur divers sujets : développer un Wikifier, développer un parser, analyser les émotions des articles de presse, utiliser le web scraping pour la recherche… En utilisant majoritairement le code de programmation Python, et d’autres outils comme Europresse et IramuteQ, les étudiants du M2 IET ont obtenu des résultats intéressants et encourageants notamment grâce aux différentes compétences acquises durant cette deuxième année de formation. Nous détaillerons ci-après le travail réalisé à partir du sujet « L’Opinion Mining et l’analyse textuelle au service de la communication : le cas de l’entreprise LU ».
Contexte de l’étude
2L’essor d’internet et du numérique, popularisé sous l’appellation du « web 2.0 » au début des années 2000 par Tim O’Reilly, a permis la démocratisation de l’information grâce à la disponibilité croissante des données rendue possible par le développement des nouvelles technologies de l’information et de la communication (NTIC). L’apparition des réseaux sociaux et du web social a provoqué des changements considérables tant au niveau sociétal qu’au niveau économique. Certaines entreprises et marques restent cependant très sensibles à ces nouveaux moyens de communication, d’autant plus qu’ils font face à une inversion du savoir : ce sont les jeunes générations qui maîtrisent le plus ces outils (Bloch, 2012).
3Outre les aspects liés à la communication et au marketing, les gestions de crises sont très fréquentes chez les entreprises à forte notoriété qui sont d’ailleurs très attendues par les consommateurs et, au moindre faux pas, les attaquent. Aujourd’hui, toutes les grandes marques sont présentes sur les réseaux sociaux pour le côté promotionnel ou publicitaire mais peu pour le côté communicationnel (à savoir l’échange et le dialogue avec les communautés). C’est pourquoi les entreprises doivent donc se remettre en question dans leur manière de communiquer, et plus particulièrement en situation de crise.
4Pour illustrer nos propos, il est nécessaire de revenir sur les crises médiatiques et du « bad buzz » autour de Nestlé en 2010 lors de la publication d’un rapport et d’une vidéo de Greenpeace accusant l’entreprise de détruire les forêts en Indonésie, les communautés locales et l’espèce des Orangs-Outangs pour ses besoins en huile de palme (notamment ici pour la fabrication des barres chocolatées Kit Kat) et la réponse maladroite du community manager de Nestlé face aux accusations. Comment les entreprises peuvent surmonter les crises médiatiques ? Quelle communication adopter avec les technologies actuelles ?
5En réponse à cette attaque, l’entreprise Nestlé s’est excusée. Quatre ans après, le groupe agro- alimentaire a ouvert une cellule avec des spécialistes d’Internet et des réseaux sociaux (tel que Pete Blackshaw) pour traquer tous les commentaires et avis des internautes pour se prémunir d’éventuelles nouvelles attaques.
6Le cas de Nestlé n’est pas isolé, car de nombreuses entreprises et multinationales ont été questionnées sur leur utilisation d’huile de Palme. Pensons à Ferrero, Colgate-Palmolive, Johnson&Johnson, Pepsi. L’affaire Nestlé/Greenpeace a parfaitement illustré un cas très connu que l’on appelle « l’effet Streisand3 ».
7Ces crises de communication autour de l’affaire Nestlé/Greenpeace nous ont inspiré une étude sur la plateforme mondiale Change.org. Nous avons souhaité analyser l’opinion des commentaires laissés par les internautes sur une pétition concernant l’huile de palme, mise en ligne il y a trois ans : « LU : stop à l’utilisation de l’huile de palme » et qui a atteint plus de 232 040 signatures. Cette pétition a également été reprise sur un autre site avec 37 337 signatures4.
8Rappelons que LU est une des nombreuses marques du groupe Mondelez International et qu’elle n’en est pas à sa première gestion de crise. En effet, l’entreprise avait déjà fait parler d’elle en 2001 avec la fuite du plan social dans la presse annonçant plusieurs fermetures d’usines et d’un licenciement massif (Malaval & Zarader, 2007). Ou encore le boycott lancé sur Facebook en 2018 contre l’une des filiales du groupe, Centrale Danone au Maroc, qui a causé la perte de 50 % de son chiffre d’affaires (Danone, géant français de l’agroalimentaire qui, en 2007, avait vendu LU au groupe américain Kraft Foods). Cette action, lancée par un anonyme, avait pour but d’accuser ces trois marques de faire du profit en fixant des prix élevés sur les produits distribués dans le royaume (ce qui rappelle le boycott de 2014 lancé par la Fédération marocaine des droits du consommateur et soutenu par l’exécutif afin de manifester contre la hausse du prix des produits laitiers dont les yaourts).
9Malgré cette image ternie par la presse et les réseaux sociaux, l’entreprise LU a su se faire oublier sur les différents scandales médiatiques qui lui ont fait pression. Cet exemple est notamment assez connu en communication et marketing pour illustrer les gestions de crise.
Méthodologie : collecte, traitement et analyse
10En se basant sur le travail réalisé par Nikos Smyrnaios, Franck Bousquet et Emmanuel Marty sur la mobilisation en ligne contre la loi travail en 2016, nous avons jugé pertinent de faire cette étude avec une nouvelle méthodologie et une autre vision sur l’e-réputation et les crises médiatiques liées aux scandales médiatiques des entreprises. Notre méthodologie est à la fois technique et scientifique par son approche des sciences humaines et sociales, et de l’informatique. Notre étude est basée sur plusieurs étapes, dont trois qui relèvent de la programmation5 :
-
la collecte des commentaires à partir de l’API de la plateforme Change.org ;
-
le traitement des commentaires ;
-
l’analyse et l’évaluation de la subjectivité (0 ; 1) et de la polarité (-1 ; 1).
11Les outils utilisés pour sa réalisation sont des outils de traitement automatique de langage (TAL) avec des scripts Python, et le logiciel d’analyse textuelle IRaMuTeQ (Ratinaud, 2008). A partir des résultats, nous placerons nos différentes analyses textuelles selon une grille définie par les critères de polarité et de subjectivité. Cette grille servira tout au long de l’étude.
12La première étape de cette étude consiste à recueillir les informations nécessaires (ici, les commentaires laissés par les internautes) à partir du site Change.org. En récupérant l’adresse URL de la pétition et en utilisant l’API de la plateforme6, nous permettons à notre script d’extraire les informations de la page HTML par du web scraping et de les écrire sur un fichier au format « pickle » (bibliothèque de sérialisation). Les commentaires sont enregistrés au nombre de 10 pour chaque affichage (paramètre par défaut de la page HTML du site). Le temps de collecte est décidé à 3 secondes par collecte.
13Tous les résultats sont donc enregistrés grossièrement dans le fichier « hpalme.pkl ». Une fois ce fichier écrit, nous traitons ces données en les rendant utilisables par le logiciel d’analyse IRaMuTeQ, en y ajoutant des paramètres de formatage pour avoir en sortie un fichier au format « txt ».
14Grâce au formatage des données pour l’import du corpus dans IRaMuTeQ (entêtes avec les composantes : Nom, Date, Ville, Pays, Likes, Id, Comment Id), tous les résultats sont donc enregistrés cette fois-ci dans le fichier « hpalme.txt ».
15La dernière étape est d’évaluer la polarité et la subjectivité des commentaires à partir de notre fichier qui compose notre corpus « hpalme.txt ». Cette étape est possible grâce à la bibliothèque « TextBlob » importée dans notre script python.
16Une fois les données traitées par le script « Traite.py », nous aurons cette-fois ci en sortie quatre sous-corpus nommés ainsi :
-
Objectif et positif ;
-
Objectif et négatif ;
-
Subjectif et positif ;
-
Subjectif et négatif.
17Ces sous-corpus permettent d’avoir des résultats différents par rapport aux analyses de données textuelles qui suivent la procédure et d’ainsi les classer selon notre grille évoquée ultérieurement.
18Les quatre fichiers en sortie correspondent aux différents critères d’évaluation et d’analyse :
-
Objectif et positif : fichier « po.txt » ;
-
Objectif et négatif : fichier « no.txt » ;
-
Subjectif et positif : fichier « ps.txt » ;
-
Subjectif et négatif : fichier « ns.txt ».
19Ces fichiers seront analysés dans la suite de l’étude séparément puis dans un corpus global regroupant les quatre sous-corpus cités.
20En se basant sur notre grille d’analyse citée précédemment, nous pouvons dès à présent placer nos différents corpus en fonction des critères évoqués.
21Nous citons quelques exemples en prenant ces extraits de commentaires en fonction de la polarité et la subjectivité évaluées dans chaque sous-corpus :
-
Négatif/objectif : « Marre que l’homme détruise sa propre planète et va continuer avec les… »
-
Négatif/subjectif : « cela fait déjà 10 ans que je boycotte les produits à base d’huile de palme »
-
Positif/subjectif : « De quel droit l’homme détruit la nature qui n’est pas sa propriété ? La nature est à la disposition de tous les êtres vivants sans exception et l’huile de palme ne nous est pas indispensable que je sache ! »
-
Positif/objectif : « Je suis maman d’un enfant, j’aimais les biscuits Lu, mais depuis quelques années déjà, je les abandonne au profit d’autre marque n’utilisant pas d’huile de palme dans la fabrication de leurs biscuits. Je ne pense pas être un cas unique ! regarder la progression de marque telle que “Jaquet”, qui communique sur l’absence d’huile de palme dans leurs produits ! à bon entendeur ! »
Résultats et analyses
22Le logiciel IRaMuTeQ propose un ensemble d’outils permettant d’analyser des corpus de textes en s’appuyant sur le logiciel R et sur le langage de programmation Python. Nous indexons plusieurs corpus dans le logiciel : les sous-corpus avec la polarité et la subjectivité, et un corpus global regroupant les sous-corpus. Grâce à cette hiérarchie, l’analyse des données est facilitée et permet un rendu plus travaillé par cette séparation de corpus (ciblage cas par cas).
23Avant de travailler sur les sous-corpus, il est nécessaire de filtrer l’ensemble quand on importe le corpus ou les sous-corpus en supprimant le « bruit » ou les « mots vides » (stopwords) : le, la, les, du, de, avec, vous, nous, ils, il, etc.
24Nous avons effectué deux analyses par nuage de mots. La première analyse permet d’avoir une vue d’ensemble générale sur le corpus global avec tous les commentaires confondus. De cette analyse ressortent les mots suivants : huile, palme, produit, planète, singe, animal.
Figure 1. Nuage de mots après suppression des termes récurrents.
25Dans un second temps, nous avons filtré notre corpus en écartant les mots cités ci- dessus, qui sont les termes récurrents. À partir de cette nouvelle analyse, on remarque que les termes les plus forts et les plus présents dans notre corpus sont les plus péjoratifs également : détruire, arrêter, massacre, déforestation, nature, stop, boycotter, destruction. Nous avons dans un premier temps une préanalyse de la polarité des mots utilisés dans les commentaires. Le nuage de mots dans IRaMuTeQ ne repose que sur la fréquence des mots dans le corpus. Il n’y a donc aucune relation entre ces mots.
Figure 2. Répartition des analyses « nuage de mots » en fonction des critères d’évaluation de la polarité et de la subjectivité des quatre sous-corpus.
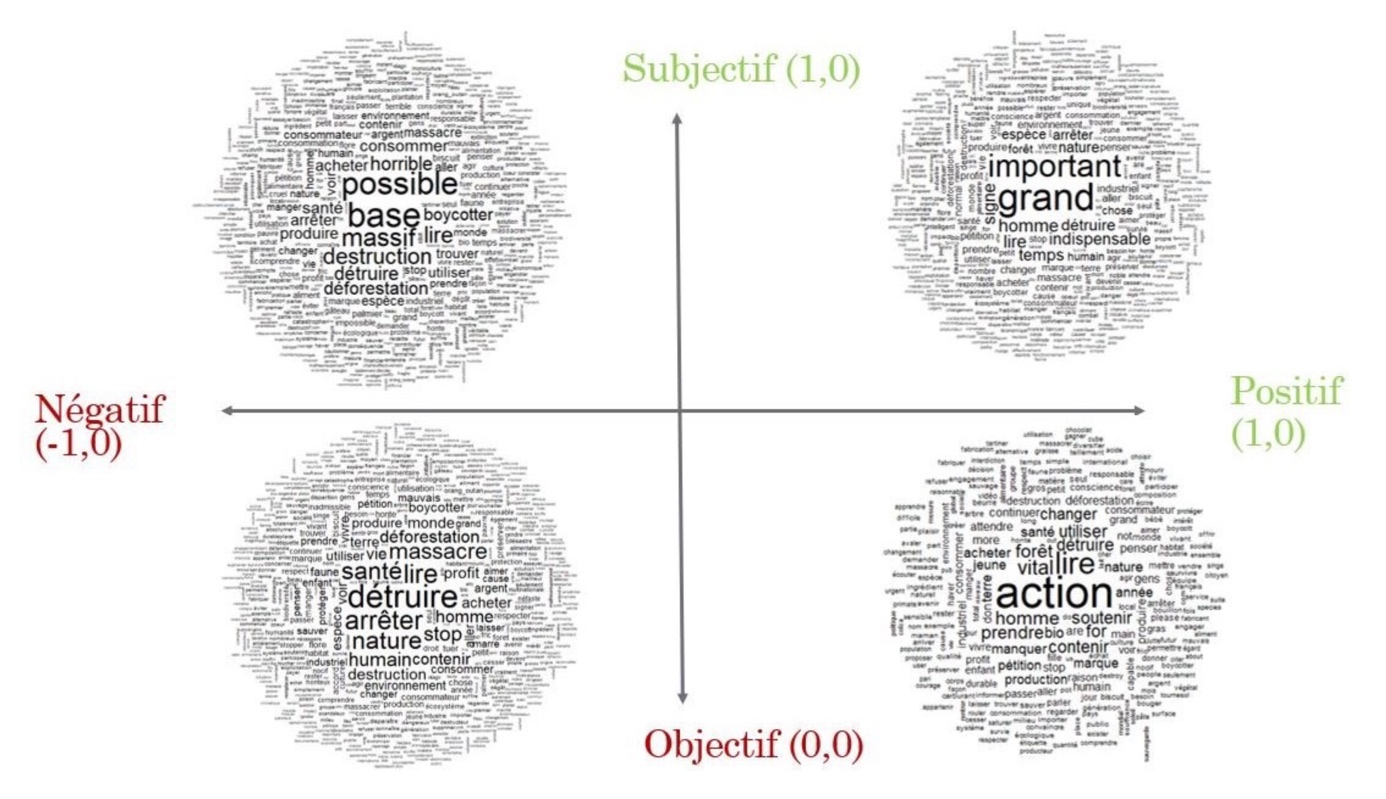
26Nous avons ensuite réalisé cette même étape pour chaque sous-corpus en fonction de la polarité et de la subjectivité obtenues.
Tableau 1. Répartition des termes récurrents pour l’analyse « nuage de mots » en fonction des sous-corpus
|
Corpus |
Récurrence des mots |
|
Subjectif/Positif |
Important, grand, homme |
|
Objectif/Positif |
Action, soutenir, forêt, vital |
|
Objectif/Négatif |
Détruire, arrêter, massacre, déforestation |
|
Subjectif/Négatif |
Destruction, détruire, déforestation, boycotter |
27En fonction de notre grille d’analyse, nous pouvons placer nos « nuages de mots » en fonction des critères d’évaluation (polarité et subjectivité) comme ce qui a été fait précédemment.
28De même que pour le nuage de mots, nous avons procédé par deux analyses. La première concerne une analyse générale des similitudes. La deuxième est filtrée par la suppression des termes récurrents (huile, palme, produit). Les termes retenus sont les suivants : détruire, nature, massacre, arrêter, déforestation, boycotter, santé, homme, humain, destruction.
29L’ADS est utilisée sous forme de graphes pour décrire des représentations sociales à partir de questionnaires d’enquêtes. Pascal Marchand et Pierre Ratinaud ont intégré au logiciel IRaMuTeQ l’analyse des similitudes d’une matrice textuelle.
Figure 3. Analyse des similitudes après suppression des termes récurrents
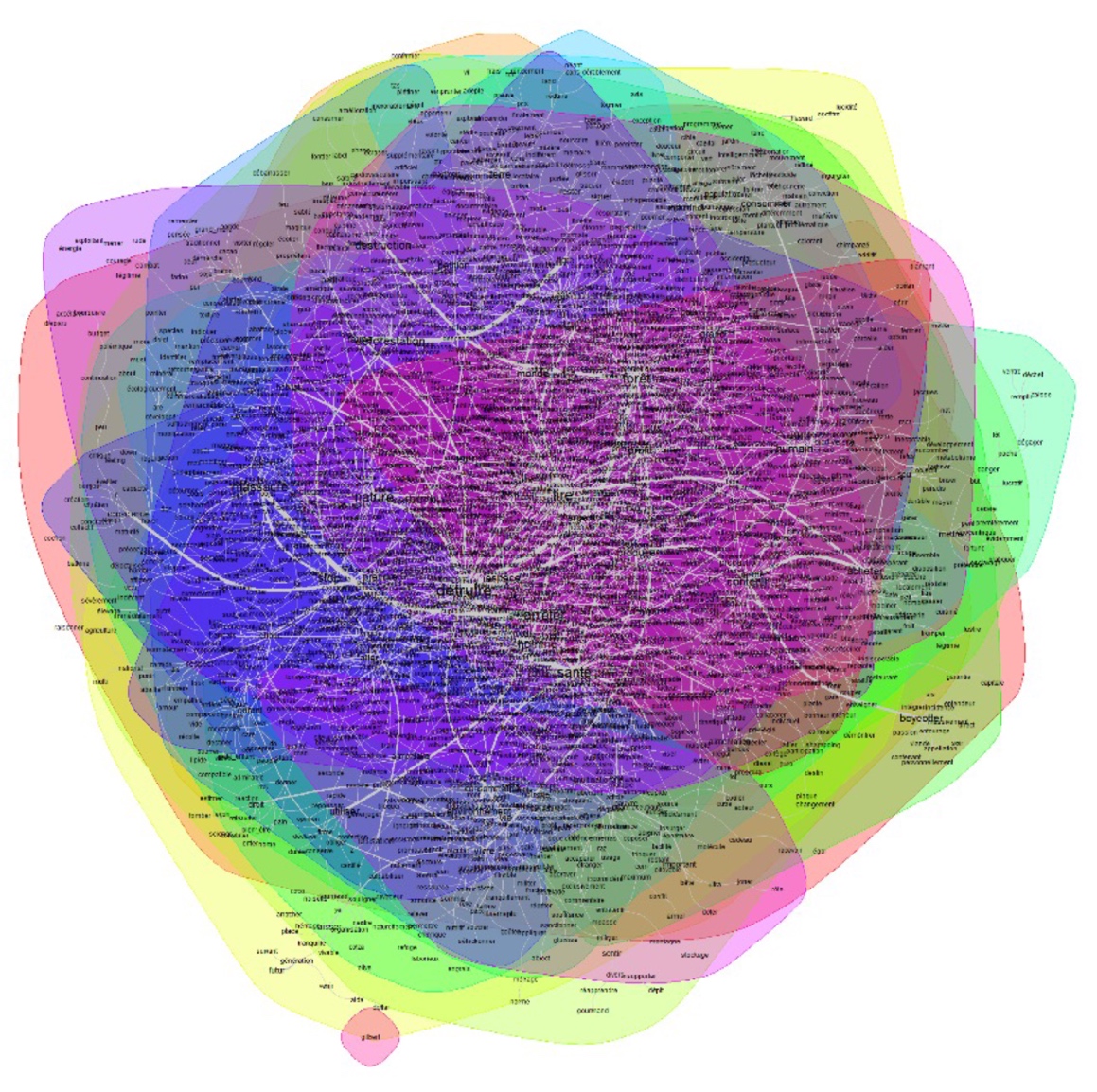
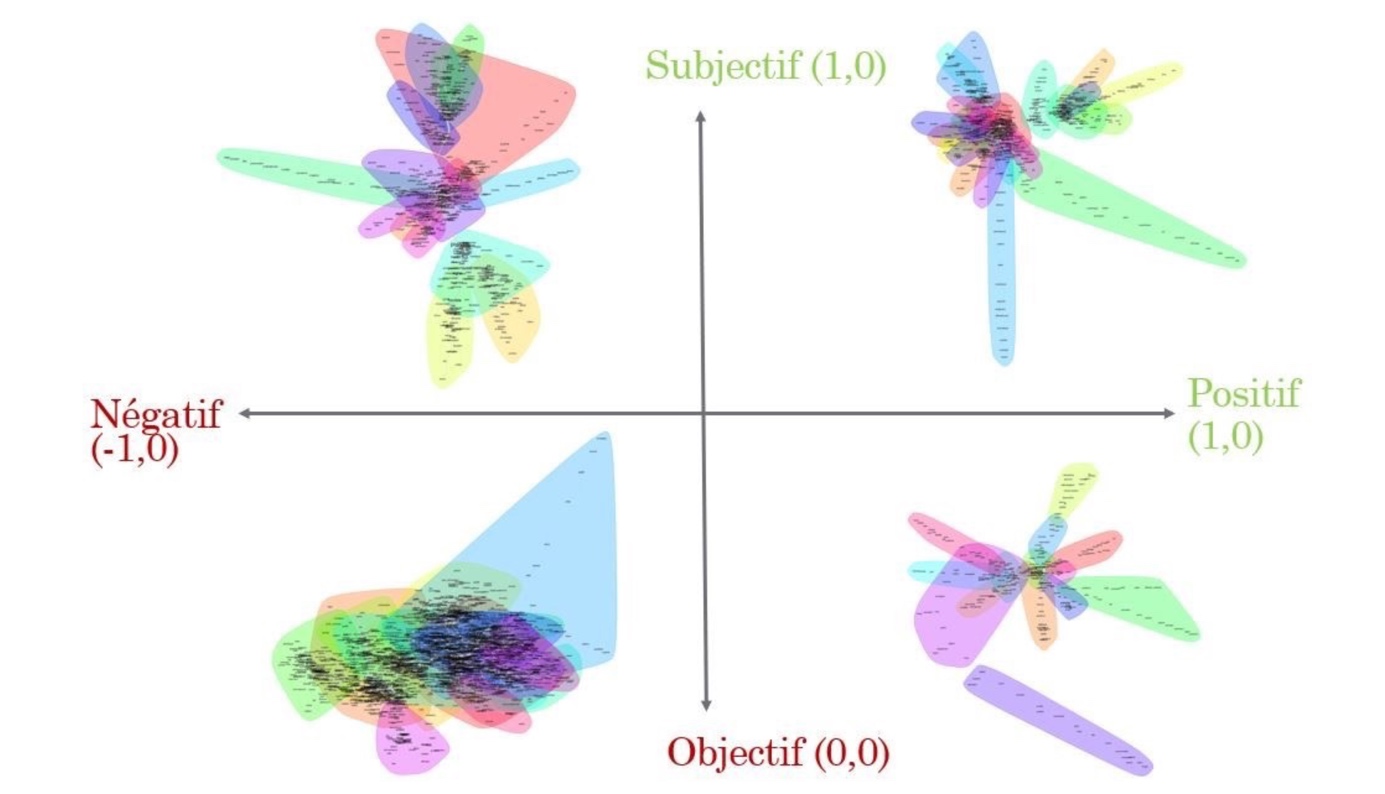
30Si l’on suit notre plan précédent, nous avons également placé nos différentes analyses des similitudes en fonction des sous-corpus, sur notre grille d’analyse.
Figure 4. Les quatre analyses des similitudes placées sur la grille en fonction des critères d’évaluation de la polarité et de la subjectivité de nos sous-corpus
31L’étude statistique est faite à partir du corpus global et nous avons obtenu : 12 048 textes, 251 186 occurrences, 9 380 formes, 4 807 hapax et une moyenne de 20,85 occurrences par texte.
32Ces informations statistiques nous permettent d’avoir une vue globale sur notre corpus, et qui peuvent être utilisées par la suite en fonction des analyses voulues par sous-corpus.
Figure 5. Analyse statistique globale du corpus
33La méthode Reinert (équivalente à la méthode Alceste) propose une classification hiérarchique descendante selon la méthode décrite par Reinert. Elle est proposée selon trois modalités :
-
Classification simple sur texte ;
-
Classification simple sur segment de texte (ST) ;
-
Classification double sur regroupement de segments de texte (RST).
34Nous l’avons appliqué à chaque sous-corpus et non au corpus général.
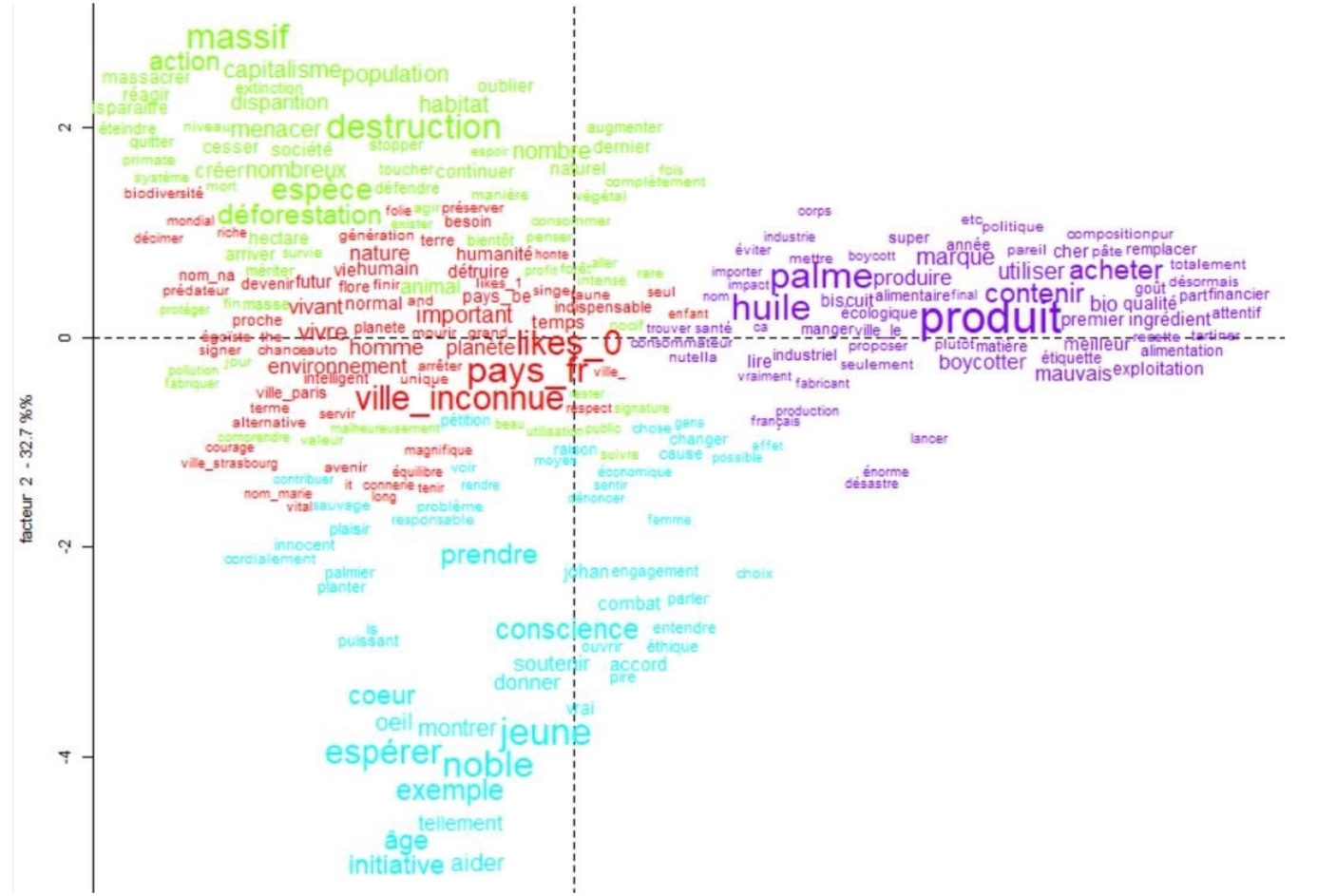
35L’exemple le plus parlant est le dendrogramme qui a défini quatre classes par thématique pour le corpus « positif/subjectif » :
-
Classe 1 à 38,4 % : vivre, important, vivant ;
-
Classe 2 à 13,6 % : destruction, massif, espèces, déforestation, action ;
-
Classe 3 à 13,8 % : jeune, noble, espérer, conscience ;
-
Classe 4 à 34,3 % : produit, huile, palme, contenir, acheter.
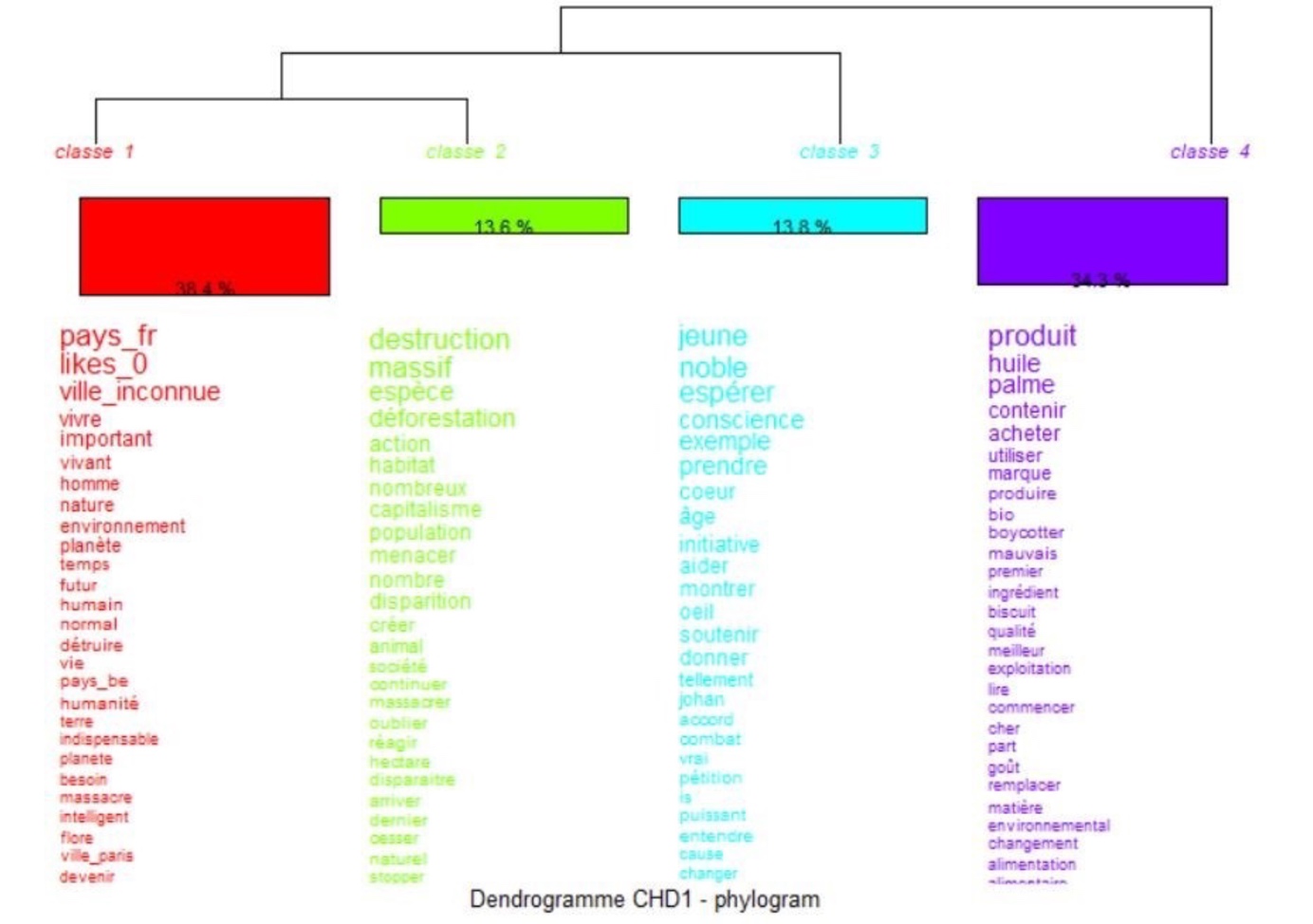
36De cette même analyse, nous pouvons établir l’analyse factorielle des correspondances (AFC), proposée par le logiciel. Cette analyse est basée sur un tableau de contingence à deux dimensions qui croise les formes actives et les variables, en faisant apparaître des relations lexicales entre elles. L’objectif est de mettre en évidence la distance entre les classes de notre corpus, représentées par les couleurs ci-dessus du dendrogramme (classe de la CHD). On peut voir que certaines classes et/ou variables se rapprochent et/ou s’opposent. On peut également obtenir à partir du graphique une hiérarchisation de l’information contenu dans notre corpus.
37Les résultats permettent d’avoir une liste des mots les plus récurrents dans les différents corpus de textes que nous avons défini, des analyses plus poussées (nuage de mots, similitudes, statistiques, AFC) en filtrant les mots du corpus. Le filtre est fait de façon manuelle et complètement instinctivement, ce qui peut définir une limite à cette étude.
38De manière générale, nous avons remarqué que les mots les plus récurrents étaient essentiellement négatifs et péjoratifs (détruire, nature, massacre, arrêter, déforestation, boycotter, santé, homme, humain, destruction). C’est en ces termes-là que l’entreprise LU doit se concentrer pour établir un nouveau discours et mettre en place une nouvelle stratégie de communication pour répondre aux crises médiatiques (comme ici : une pétition en ligne lancée par les consommateurs).
39Toutes les analyses effectuées ont été produites à partir du logiciel IRaMuTeQ, ce qui est un avantage comme un inconvénient. Les perspectives seraient de reproduire cette étude à partir d’un autre logiciel d’analyse textuelle comme Tropes par exemple.
40De plus, nous nous sommes basés uniquement sur la fouille d’opinion (Dave et al, 2003) qui utilise comme terminologie : subjectivité et polarité (alors qu’elle comprend également les sentiments, l’opinion…). Nous ne parlons pas à proprement dit d’analyse de sentiment (Pang and Lee, 2007) qui peut être étudiée à partir d’un corpus textuel téléchargé sur Europresse et travaillée à partir d’un dictionnaire des émotions (cf. les encadrés de la Figure 1). Ici, nous avons souhaité classer un avis sur une axiologie positif et négatif (Marchand, 2015).
41Le traitement automatique des langues (TAL) à travers cette étude a permis d’analyser un corpus textuel à partir d’un site grâce aux interactions entre la machine et l’homme (Katet, 2011) permises par le langage de programmation Python et les différents scripts échangés. Les ordinateurs sont d’une grande performance quant au traitement automatique d’une grande quantité de données (ici, textes écrits en langage naturel).
Figure 6. Dendrogramme résultant de l’analyse par la méthode Reinert pour le sous-corpus « positif/subjectif ».
Conclusion
42En fonction du parcours choisi par l’étudiant, l’épreuve du « Grand Oral » peut être différente même si les modalités sont les mêmes. En fonction des spécialités, il peut être demandé à l’étudiant de réaliser une veille, une campagne de communication, de proposer ou développer un dispositif innovant pour répondre à la problématique de l’énoncé. En s’inspirant de cas concrets, l’étudiant adopte une posture professionnelle à travers une mise en situation « réaliste ». L’exemple choisi dans cet article a permis de rendre compte des possibilités qu’il existe pour faire de l’analyse textuelle et de l’analyse de fait/d’opinion (opinion mining). Ce type d’exercice peut être utile pour les entreprises afin d’élaborer des campagnes de publicité pour se défendre en cas d’attaque ou de pression externe, favorisant ainsi l’aide à la décision. Cette méthodologie peut être appliquée à n’importe quel sujet (buzz médiatique : #balancetonporc, affaire Lactalis, etc.) ou faits d’actualité (sujets politiques comme : Nutriscore, Gilets jaunes, pénurie d’essence, Guerre Russie/Ukraine, etc.). Ce type d’exercice permet de travailler sur l’e-réputation et l’influence afin de mettre au point des stratégies de communication factuelles en réponse aux objections argumentées des détracteurs. La collecte, le traitement et l’analyse de données sont des savoirs nécessaires aujourd’hui dans les métiers de la data, notamment en intelligence économique et compétitive. Cette approche pluridisciplinaire, permettant d’aborder le traitement automatique de langage, le machine learning et le data mining, est intéressante pour obtenir une méthodologie complète et ainsi réaliser une étude ambitieuse.
Figure 7. Analyse factorielle des correspondances (AFC) à partir du sous-corpus « positif/subjectif » en fonction des classes de la CHD obtenues par la méthode Reinert.
Bibliographie
Bloch, Emmanuel. 2012. Communication de crise et médias sociaux : anticiper et prévenir les risques d’opinion – Protéger sa e-réputation – Gérer les crises. Paris, Dunod.
Dave, Kushal, Steve Lawrence & David M. Pennock. 2003. « Mining the peanut gallery : Opinion extraction and semantic classification of product reviews ». In Proceedings of the 12th international conference on World Wide Web, pp. 519-528. ACM.
Katet, Soufiene. 2011. Analyse sémantique d’opinion (mémoire de maitrise Produits de l’Information Spécialisée et Médiation Électronique (PISME)). Université Lille 3 Charles De Gaulle, France.
Malaval, Catherine & Robert Zarader. 2007. « L’affaire LU : autopsie d’une crise d’un nouveau type. Magazine de la communication de crise et sensible ». [En ligne]. Url : http://www.communication-sensible.com/articles/article0174.php?PHPSESSID=e290987e113ef64532f86369 b1ae8c42
Marchand, Morgane. 2015. Domaines et fouille d’opinion : une étude des marqueurs multi- polaires au niveau du texte (thèse de doctorat en informatique). Université Paris Sud, France.
Pang, Bo & Lillian Lee. 2007. « Opinion mining and sentiment analysis. Foundations and Trends » in Information Retrival, 2 : 1-2.
Ratinaud, Pierre. 2008. « Interface de R pour les Analyses Multidimensionnelles de Textes et de Questionnaires » (Version 0.7 alpha 2). Toulouse, France : LERAS. Url : http://www.iramuteq.org
Smyrnaios, Nicolas, Franck Bousquet & Emmanuel Marty. 2016. « La mobilisation en ligne contre la Loi travail : enquête sur les réseaux et les discours. » [En ligne]. Url : http://ephemeron.eu/1804
Notes
1 Les étudiants des parcours ACNCC et DEDI (mention Création Numérique) et les étudiants des parcours DASI, CDE et CIMPN (mention Information-Communication) doivent répondre à cette épreuve obligatoire
2 Depuis, le master est dispensé sur deux ans et a été renommé en Master Data Analytics et Stratégie de l’Information (DASI). Plus d’informations : https://www.univ-tln.fr/IMG/pdf/master-infocom-datas.pdf
3 Affaire Streisand de 2003 : tentative de censure/camouflage en ligne ayant pour conséquence contraire l’accélération de la propagation du contenu que l’on a souhaité cacher.
4 www.i-boycott.org/campaigns/lu-stop-a-l-huile-de-palme
5 Le code est accessible sur la plateforme GitHub : https://github.com/ClaraGalliano/Grand-Oral_M2-IET
6 Depuis le 30 octobre 2017, l’API du site Change.org est hors service : https://help.change.org/s/article/Change-org-API?language=fr
Pour citer ce document
Quelques mots à propos de : Clara Galliano
Laboratoire IMSIC UTLN-AMU, Université de Toulon, France. Courriel : clara.galliano@univ-tln.fr